


Комментарии участников:



Вы уже сделали обзор устройства? Определили слабые и сильные стороны, проверили функции и протестировали их вместе с людьми, слабо понимающими в технике? Есть сравнения с аналогичными девайсами?
Или так просто сказали «горизонт завален»?
 источник: i63.fastpic.ru
источник: i63.fastpic.ru
Или так просто сказали «горизонт завален»?
источник: i63.fastpic.ru 
Если вы знакомы с технологией распознавания речи, то это устройство похоже является прорывом — слитная речь, да еще неограниченной длины, такого даже Apple в своем Siri так и не смогли допилить, как и Google с MS и это несмотря на их бюджеты
См ссылку на сайт
См ссылку на сайт

Увы, прорывом не является, т.к. при понимания 100 команд о «слитности речи» можно вообще даже и не думать — это вообще не проблема, а лишь маркетинговый трюк.
Данный «прорыв» работал ещё в windows95 для распознавания команд типа «свернуть окно», это всего лишь его адаптация под копеечный микропроцессор и DSP, но почему-то по цене смартфона.
P.S. Speereo занимается не высококачественной обработкой речи, а оптимизацией обработки речи по скорости. Это две разные вещи.
Данный «прорыв» работал ещё в windows95 для распознавания команд типа «свернуть окно», это всего лишь его адаптация под копеечный микропроцессор и DSP, но почему-то по цене смартфона.
P.S. Speereo занимается не высококачественной обработкой речи, а оптимизацией обработки речи по скорости. Это две разные вещи.
P.P.S. Сам занимаюсь распознаванием речи. Вот самая клёвая работа 2014 года по теме:
https://gigaom.com/2014/12/18/baidu-claims-deep-learning-breakthrough-with-deep-speech/ — научпоп, arxiv.org/pdf/1412.5567.pdf — сама работа.
https://gigaom.com/2014/12/18/baidu-claims-deep-learning-breakthrough-with-deep-speech/ — научпоп, arxiv.org/pdf/1412.5567.pdf — сама работа.
Уважаемый, если вы действительно
P.S. Если же вы все-таки участвовали в разработке подобных систем — было бы крайне интересно ознакомиться с последними веяниями в технологии распознавания русской речи (ссылки, если можно). Спасибо заранее.
Сам занимаюсь распознаванием речи. Вот самая клёвая работа 2014 года...то должны понимать, что в данном случае вся фишка — в распознавании именно русскоязычной речи, а это — несколько сложнее (англоязычную речь вполне сносно и уже давно «понимает» тот же Siri от Apple).
P.S. Если же вы все-таки участвовали в разработке подобных систем — было бы крайне интересно ознакомиться с последними веяниями в технологии распознавания русской речи (ссылки, если можно). Спасибо заранее.
Собственно, распознавать саму русскую речь ненамного сложнее (фонем примерно столько же), сложнее именно то, что на выходе системы не 500 тыс. словоформ, как в английском, а 5 млн словоформ, которые ещё нужно согласовывать по родам, числам, падежам — сложнее лингвистическая модель.
У Speereo есть разработка, которая делает распознавание на 1 млн слов. Они оптимизировали систему по скорости, что она работает даже на слабеньких компьютерах. Но с качеством на большом словаре у них, естественно, беда. Особенно, с качеством в присутствии шума — а это и есть направление прогресса в наше время.
Как вы понимаете, в случае с разработкой пульта, распознающего 100 команд, обо всей этой сложности говорить не приходится, лингвистической модели в таком пульте просто нет.
У Speereo есть разработка, которая делает распознавание на 1 млн слов. Они оптимизировали систему по скорости, что она работает даже на слабеньких компьютерах. Но с качеством на большом словаре у них, естественно, беда. Особенно, с качеством в присутствии шума — а это и есть направление прогресса в наше время.
Как вы понимаете, в случае с разработкой пульта, распознающего 100 команд, обо всей этой сложности говорить не приходится, лингвистической модели в таком пульте просто нет.
Вот ЦРТ, который этим занимается уже 15 лет: www.speechpro.ru/
Вот аудио-видео распознавание (ещё слабенькое, на уровне обычного распознавания от гугла, но ребята стараются): realspeaker.net/ru/
А вот обзор Dragon Dictation от 2013 года
 www.ferra.ru/ru/apps/fun/2013/03/18/dragon-dictation---raspoznavanie-golosa-v-tekst.html#.VMjvLDWlilM
www.ferra.ru/ru/apps/fun/2013/03/18/dragon-dictation---raspoznavanie-golosa-v-tekst.html#.VMjvLDWlilM
Я подобную систему на 100 слов для русского языка пробовал ещё в 2005м году, а для команд — в 1998м году, заметьте, команды можно было диктовать на любом языке.
Ну и гугл свой «окей, гугл» дотачивает, вполне сносно работает для распознавания тех же поисковых запросов голосом. Заметьте, там словарь — миллионы слов.
Все эти работы просто шикарны по сравнению с этой поделкой от Speereo.
www.speereo.com/page_technology.html?language=ru
Дело в том, что у голосовых команд есть одна проблема: вы два раза не повторяете дословно одну и ту же команду: вы меняете интонации, растягиваете или сокращаете звуки.
Поэтому «точность 99.7%» и «точность 97%» может быть только при воспроизведении wav-файлов со звуком, и в достаточно тихой комнате. Если будет громко орать телевизор, которым вы пытаетесь управлять голосом — качество распознавания существенно упадёт.
Вот аудио-видео распознавание (ещё слабенькое, на уровне обычного распознавания от гугла, но ребята стараются): realspeaker.net/ru/
А вот обзор Dragon Dictation от 2013 года
 www.ferra.ru/ru/apps/fun/2013/03/18/dragon-dictation---raspoznavanie-golosa-v-tekst.html#.VMjvLDWlilM
www.ferra.ru/ru/apps/fun/2013/03/18/dragon-dictation---raspoznavanie-golosa-v-tekst.html#.VMjvLDWlilMЯ подобную систему на 100 слов для русского языка пробовал ещё в 2005м году, а для команд — в 1998м году, заметьте, команды можно было диктовать на любом языке.
Ну и гугл свой «окей, гугл» дотачивает, вполне сносно работает для распознавания тех же поисковых запросов голосом. Заметьте, там словарь — миллионы слов.
Все эти работы просто шикарны по сравнению с этой поделкой от Speereo.
www.speereo.com/page_technology.html?language=ru
Дело в том, что у голосовых команд есть одна проблема: вы два раза не повторяете дословно одну и ту же команду: вы меняете интонации, растягиваете или сокращаете звуки.
Поэтому «точность 99.7%» и «точность 97%» может быть только при воспроизведении wav-файлов со звуком, и в достаточно тихой комнате. Если будет громко орать телевизор, которым вы пытаетесь управлять голосом — качество распознавания существенно упадёт.
Ещё раз табличка про качество распознавания речи в условиях шумов:
https://gigaom2.files.wordpress.com/2014/12/baidu1.jpg?quality=80&strip=all
WER — процент ошибок распознавания слова в спонтанной речи на английском языке, словарь 500 тысяч слов.
В общем, без учета существования шумов, получается следующий алгоритм работы со звуком:
«Так, все посторонние — заткнитесь и перестаньте ходить, бегать, стучать вилками, слушать музыку в наушниках, говорит — один, остальные замерли. Уважаемый пользователь, здравствуйте. Какая будет ваша команда?». В общем, прогресс есть, но пока что с речью не всё идеально.
Профессионалы, работающие с системами распознавания, покупают спец. микрофоны, т. наз. «microphone array», которые устойчивы к шумам, потому что программно настраиваются на звук в одной области. Так же поступает Xbox, в котором тоже стоит microphone array. Ну а у журналистов микрофоны обмотаны поролоном.
https://gigaom2.files.wordpress.com/2014/12/baidu1.jpg?quality=80&strip=all
WER — процент ошибок распознавания слова в спонтанной речи на английском языке, словарь 500 тысяч слов.
В общем, без учета существования шумов, получается следующий алгоритм работы со звуком:
«Так, все посторонние — заткнитесь и перестаньте ходить, бегать, стучать вилками, слушать музыку в наушниках, говорит — один, остальные замерли. Уважаемый пользователь, здравствуйте. Какая будет ваша команда?». В общем, прогресс есть, но пока что с речью не всё идеально.
Профессионалы, работающие с системами распознавания, покупают спец. микрофоны, т. наз. «microphone array», которые устойчивы к шумам, потому что программно настраиваются на звук в одной области. Так же поступает Xbox, в котором тоже стоит microphone array. Ну а у журналистов микрофоны обмотаны поролоном.

насмешили. Теперь о том как есть на самом деле, а не в ваших фантазиях
1. Словарь системы НЕОГРАНИЧЕН
2. Это система распознавания а не сравнения с образцом
3. У ЦРТ нет работающей хоть как-то системы распознавания, они занимаются шумоочисткой и идентификацией, у realspeaker используется чужой движок, который только дополняется уровнем уточнения по движению губ.
4. По точности распознавания (и особенно в шумах) Speereo N1 в мире. Если взять любую тысячу команд и надиктовать её разными дикторами (показательный пример) и протестировать с различными движками то, Speereo API 99,4%, Google API 72%, Nuance 60%, Apple 56%. В шумах с SNR до 5 вообще никто не работает, а у нас 97%. Так что всё с точностью до наоборот. Что кстати косвенно подтверждает исследование и хотелки Baidu. Но нас они не тестировали, в отличие от Intel и Toyota.
5. Массив микрофонов стоит дорого, поэтому используется микрофон в пульте, что привычней и удобней. Профессионалы используют массив, когда их ASR превращается в тыкву, пытаются поднять SNR.
6. Именно поэтому ни американцы ни корейцы не могут выпустить такой пульт с таким набором функций, тупо ошибается на каждой второй фразе. ТО, что поставляется вместе со SmartTV стырено у нас по идее, но не работает.
7. На смартфонах используют Google и Apple (слегка оттюненный Nuance на самом деле), в задаче управления БТ — ошибки на каждой второй фразе. Да и рулить телевизором со смартфона не всем удобно. Тоже мимо.
Учите матчасть, специалист.
1. Словарь системы НЕОГРАНИЧЕН
2. Это система распознавания а не сравнения с образцом
3. У ЦРТ нет работающей хоть как-то системы распознавания, они занимаются шумоочисткой и идентификацией, у realspeaker используется чужой движок, который только дополняется уровнем уточнения по движению губ.
4. По точности распознавания (и особенно в шумах) Speereo N1 в мире. Если взять любую тысячу команд и надиктовать её разными дикторами (показательный пример) и протестировать с различными движками то, Speereo API 99,4%, Google API 72%, Nuance 60%, Apple 56%. В шумах с SNR до 5 вообще никто не работает, а у нас 97%. Так что всё с точностью до наоборот. Что кстати косвенно подтверждает исследование и хотелки Baidu. Но нас они не тестировали, в отличие от Intel и Toyota.
5. Массив микрофонов стоит дорого, поэтому используется микрофон в пульте, что привычней и удобней. Профессионалы используют массив, когда их ASR превращается в тыкву, пытаются поднять SNR.
6. Именно поэтому ни американцы ни корейцы не могут выпустить такой пульт с таким набором функций, тупо ошибается на каждой второй фразе. ТО, что поставляется вместе со SmartTV стырено у нас по идее, но не работает.
7. На смартфонах используют Google и Apple (слегка оттюненный Nuance на самом деле), в задаче управления БТ — ошибки на каждой второй фразе. Да и рулить телевизором со смартфона не всем удобно. Тоже мимо.
Учите матчасть, специалист.
1. Словарь системы НЕОГРАНИЧЕН
Ну конечно же неограничен! 1000 *произвольных* команд с *произвольными* словами распознавать может. Фантастика!
>4. По точности распознавания (и особенно в шумах) Speereo N1 в мире. Если взять любую тысячу команд и надиктовать её разными дикторами (показательный пример) и протестировать с различными движками то, Speereo API 99,4%, Google API 72%, Nuance 60%, Apple 56%.
Вот я об этом именнно и говорил. 1000 слов всего. Зато любых. Скептики посрамлены!
А для 500 тыс слов какая у вас, говорите, точность распознавания?
Надиктуйте слова от типичного пользователя: код, кот, ком, кон.
Получите 99% с типичными кухонными шумами — признАю свою неправоту.
>3. У ЦРТ нет работающей хоть как-то системы распознавания, они занимаются шумоочисткой и идентификацией, у realspeaker используется чужой движок, который только дополняется уровнем уточнения по движению губ.
Ок. С чужим движком они могут более-менее диктовку делать, а вы с какой точностью можете?
>4. В шумах с SNR до 5 вообще никто не работает, а у нас 97%
На каком количестве слов? Опять 1000?
>5. Массив микрофонов стоит дорого, поэтому используется микрофон в пульте, что привычней и удобней. Профессионалы используют массив, когда их ASR превращается в тыкву, пытаются поднять SNR.
И я о том же.
>6. Так что всё с точностью до наоборот. Что кстати косвенно подтверждает исследование и хотелки Baidu. Но нас они не тестировали, в отличие от Intel и Toyota.
Dataset доступен (хотя и не открыт), протестируйтесь и выложите результаты, вместе посмотрим. Мне можете результат на burchik@gmail.com отправить.
Вы не о том спорите, понимаете. Вас поняли, что вы общую задачу распознавания непрерывной речи решили лучше мировых фирм. А вы решили задачу распознавания ограниченного количества произвольных команд с высоким качеством.
Я не спорю, что задачу хорошего распознавания вы тоже возможно решили неплохо. Ну тогда сравнимые метрики в студию, например, те же, что в работе Baidu.
Ведь в задаче распознавания большого количества слов проблем с языковой моделью больше, чем с моделью фонем, и тут ваша точность распознавания фонем уже не считается победой.
Ну конечно же неограничен! 1000 *произвольных* команд с *произвольными* словами распознавать может. Фантастика!
>4. По точности распознавания (и особенно в шумах) Speereo N1 в мире. Если взять любую тысячу команд и надиктовать её разными дикторами (показательный пример) и протестировать с различными движками то, Speereo API 99,4%, Google API 72%, Nuance 60%, Apple 56%.
Вот я об этом именнно и говорил. 1000 слов всего. Зато любых. Скептики посрамлены!
А для 500 тыс слов какая у вас, говорите, точность распознавания?
Надиктуйте слова от типичного пользователя: код, кот, ком, кон.
Получите 99% с типичными кухонными шумами — признАю свою неправоту.
>3. У ЦРТ нет работающей хоть как-то системы распознавания, они занимаются шумоочисткой и идентификацией, у realspeaker используется чужой движок, который только дополняется уровнем уточнения по движению губ.
Ок. С чужим движком они могут более-менее диктовку делать, а вы с какой точностью можете?
>4. В шумах с SNR до 5 вообще никто не работает, а у нас 97%
На каком количестве слов? Опять 1000?
>5. Массив микрофонов стоит дорого, поэтому используется микрофон в пульте, что привычней и удобней. Профессионалы используют массив, когда их ASR превращается в тыкву, пытаются поднять SNR.
И я о том же.
>6. Так что всё с точностью до наоборот. Что кстати косвенно подтверждает исследование и хотелки Baidu. Но нас они не тестировали, в отличие от Intel и Toyota.
Dataset доступен (хотя и не открыт), протестируйтесь и выложите результаты, вместе посмотрим. Мне можете результат на burchik@gmail.com отправить.
Вы не о том спорите, понимаете. Вас поняли, что вы общую задачу распознавания непрерывной речи решили лучше мировых фирм. А вы решили задачу распознавания ограниченного количества произвольных команд с высоким качеством.
Я не спорю, что задачу хорошего распознавания вы тоже возможно решили неплохо. Ну тогда сравнимые метрики в студию, например, те же, что в работе Baidu.
Ведь в задаче распознавания большого количества слов проблем с языковой моделью больше, чем с моделью фонем, и тут ваша точность распознавания фонем уже не считается победой.
 www.slideshare.net/Speereo/speereo-42043148
www.slideshare.net/Speereo/speereo-42043148https://drive.google.com/file/d/0Bxoydfk94mGYazc3S01aMFpCT2s/view?usp=sharing
Изучайте.
По поводу словаря. Словарь неограничен (у нас свой транскриптор) и из него динамически выбирается до 10 000 фраз для распознавания.
В задачах, где не нужны миллионы словоформ, т.е. в задачах управления бытовой техникой наш па технология дает 99,9 %, а другие (несмотря на миллионы слов и крутизну в ваших глазах) — нет.
Это реальность
Ну, я же так и сказал: нормальная нишевая технология, что-то типа допиливания Sphinx, применения есть, но крайне ограничены: у пилотов истребителей или при заполнении формы во врачебной практике…
Увы, подход с HMM не масштабируется на большие словари, и вы прекрасно это знаете, только упорно используете термин «неограниченный словарь», имея в виду «небольшой словарь из произвольно выбранных слов».
Эх, где вы были в 90х!..
Сейчас потребители того же Cubic-а, Amazon Echo или любой другой системы для умного дома уже не обойдутся тысячей слов, им хочется, чтобы с ними по-человечески говорили…
Увы, подход с HMM не масштабируется на большие словари, и вы прекрасно это знаете, только упорно используете термин «неограниченный словарь», имея в виду «небольшой словарь из произвольно выбранных слов».
Эх, где вы были в 90х!..
Сейчас потребители того же Cubic-а, Amazon Echo или любой другой системы для умного дома уже не обойдутся тысячей слов, им хочется, чтобы с ними по-человечески говорили…
Добавлю к вышесказанному Константином Ламиным, что указанное вами ПО Dragon опробовано мной лично в 2014 году (iOS, iPAD3 ). Мягко говоря — не впечатлило. Объективности ради, зашел сейчас в App Store, посмотрел отзывы — ничего не изменилось. Да и позиционирует разработчик ПО лишь для надиктовки SMS и электронной почты.
P.S. Тестирую подобные системы давно, помните раньше продавались поделки типа «Горыныч» и т.п.? Т.е. общими сведениями и тенденциями владею. ))
P.S. Тестирую подобные системы давно, помните раньше продавались поделки типа «Горыныч» и т.п.? Т.е. общими сведениями и тенденциями владею. ))
Чтобы не быть голословным, планирую сначала опробовать технологию Speereo.
А вот ссылка на отчет о тестировании пульта Speaky.
А вот ссылка на отчет о тестировании пульта Speaky.

Вот только компания зарегистрирована в Лондоне ещё в 98 году.
Отрадно, что R&D и производство у них в основном наше, но остальное:
Как-то не впечатляет. Помнится, ещё в 2002-2003 году игрался с голосовым управлением и набором текста.
Отрадно, что R&D и производство у них в основном наше, но остальное:
Компания Speereo уже 15 лет занимается распознаванием речи
В основе пульта лежит «облачная» система распознавания, созданная в стенах Speereo
Как-то не впечатляет. Помнится, ещё в 2002-2003 году игрался с голосовым управлением и набором текста.
12 тысяч дорого, до 3 нужно снижать цену.
Железа там аккурат на 2-3 тысячи.
Обработка голоса один фиг у них на серверах происходит.
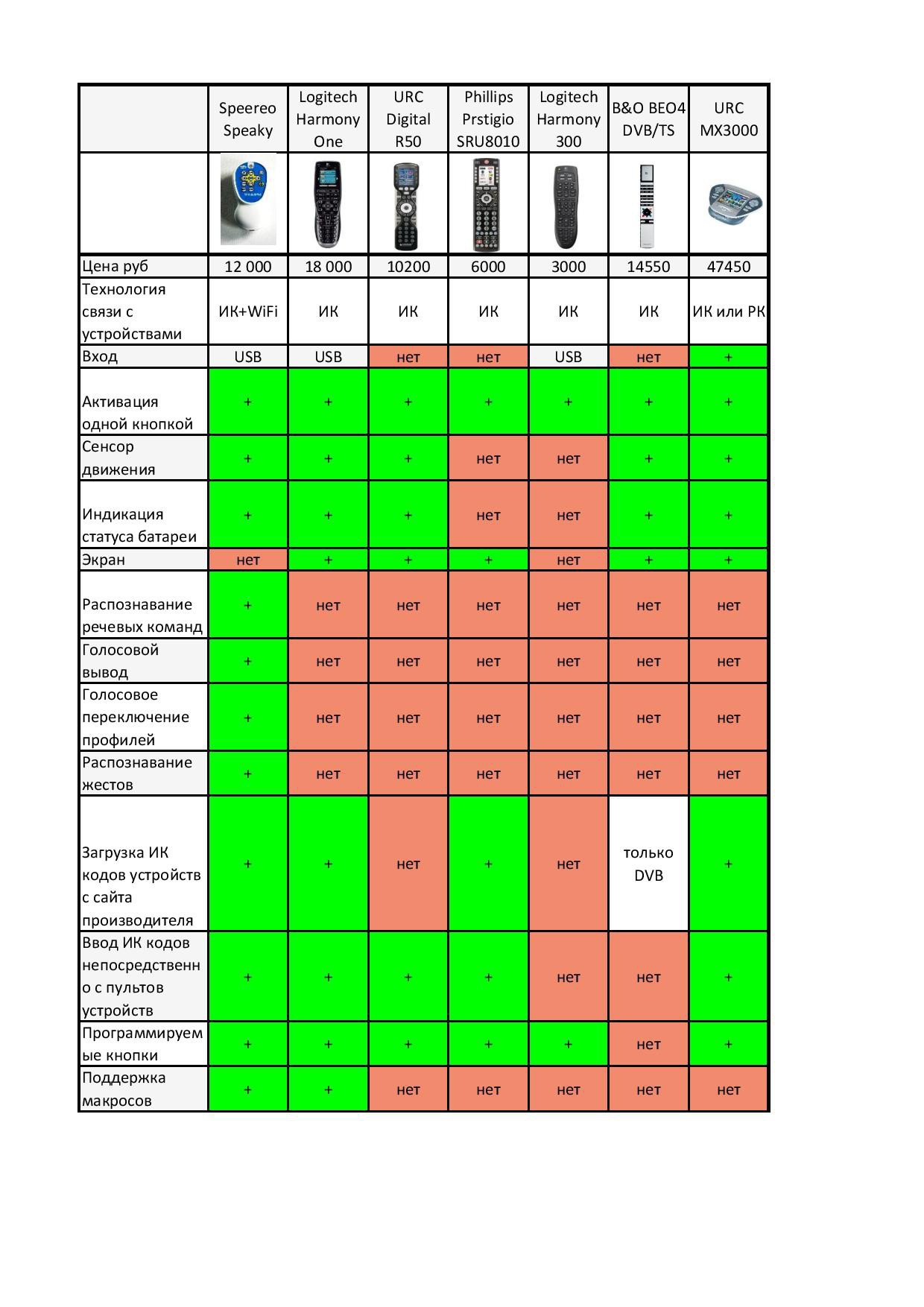
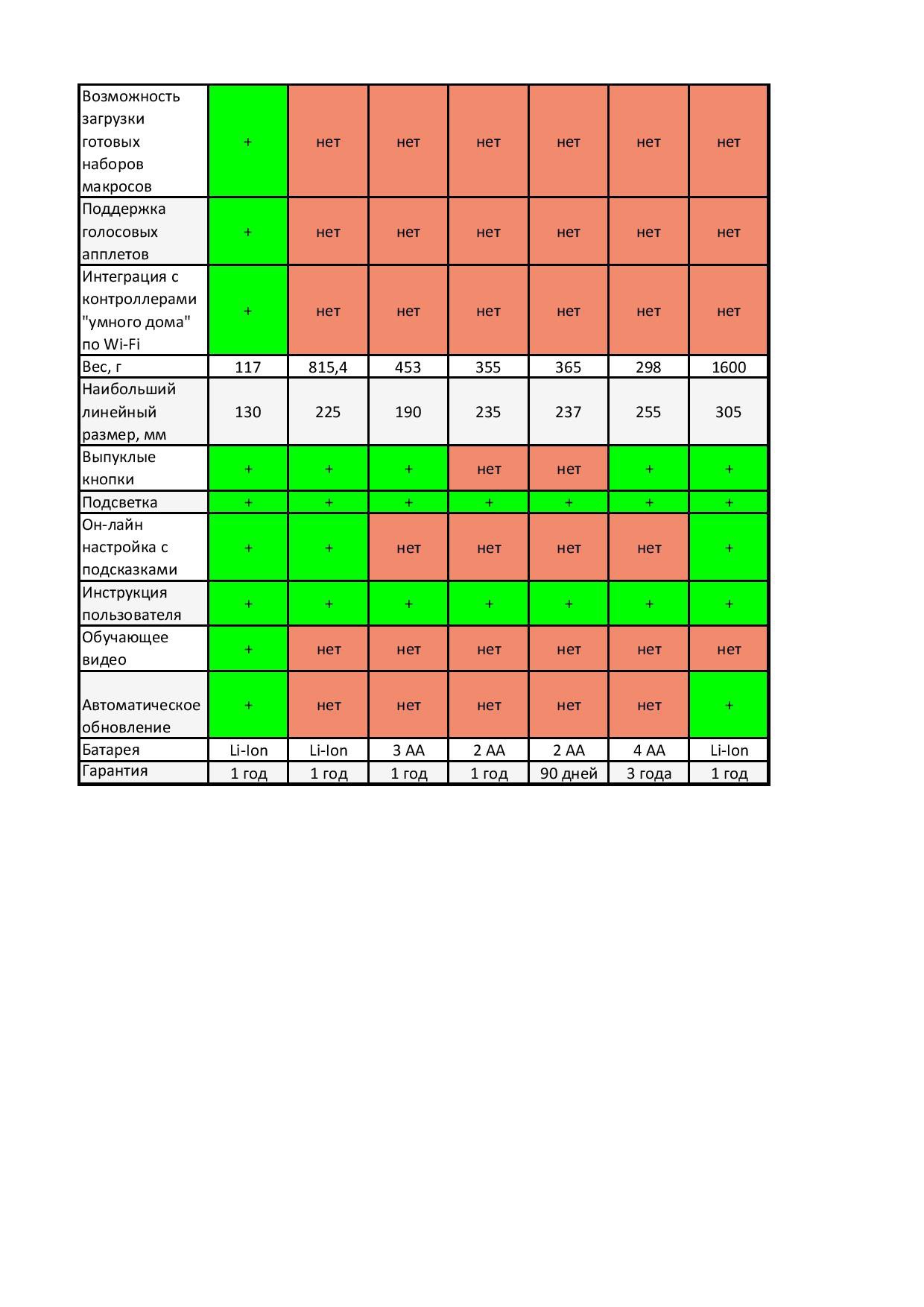
По моей ссылке (выше) пройдите, там за три тысячи какой-то простенький Логитеч лежит )) (см. сравнительные таблицы устройств):
 источник: speaky.speereo.com
источник: speaky.speereo.com
 источник: speaky.speereo.com
источник: speaky.speereo.com
источник: speaky.speereo.comисточник: speaky.speereo.com 
Ну да. Вот с ценой около 3000 можно будет конкурировать.
Но обратите внимание — только у российского и у того, дешевого, за 3 000 рублей который — нет экрана. А ведь это важно.
Но обратите внимание — только у российского и у того, дешевого, за 3 000 рублей который — нет экрана. А ведь это важно.
А зачем там экран? Там голосовой вывод (сообщений) есть. См. внимательнее табличку.
И вообще в нем много чего интересного наворочено, чего у конкурентов никогда не будет, т.к. все известные фирмы строго все фичи «дозируют» по модификациям.
И вообще в нем много чего интересного наворочено, чего у конкурентов никогда не будет, т.к. все известные фирмы строго все фичи «дозируют» по модификациям.
Тачскрин как вариант ухода от десятков кнопок. Это потому что у них голосового управления нет. Тачскрин имеет недостатки: дорого, вес, жрет батарейку и процессор, неудобно нажимать «наощупь» (вернее совсем никак), надо смотреть думать что где, легко промазать мимо кнопки. Нормальные кнопки удобнее. Для самых частых функций мы их и оставили основные. А вот для более редких но многочисленных — речевые команды. В итоге очень удобно.
