
[Разметчик vs кодер] ChatGPT сверхэксплуатирует умственный труд контрактников за $15 в час. OpenAI нанимает рабочих разовой разметки данных, обучающих AI ответам на запросы пользователей
![[Разметчик vs кодер] ChatGPT сверхэксплуатирует умственный труд контрактников за $15 в час. OpenAI нанимает рабочих разовой разметки данных, обучающих AI ответам на запросы пользователей](/story_images/662000/1683697973_26_1683697683_17_1683697662_18_1683697454_38_1683697250_67_1683697142_23_1683697116_82_1683697068_5_1683696834_36_690665_MFrR2TL_chatgpt.jpg)
ChatGPT — самый популярный чат-бот на базе искусственного интеллекта, функционирует благодаря машинному обучению, но за этим стоят люди, многие из которых получают довольно низкую зарплату. Новый отчет NBC News показывает, что OpenAI нанимает множество контрактных сотрудников в США для выполнения важной задачи разметки данных, которая требуется для обучения ChatGPT лучше отвечать на запросы пользователей. За эту ключевую работу предлагается захватывающая сумма в $15 в час.
Мы — основной трудовой класс, но без нас не было бы языковых систем на основе ИИ. Вы можете разрабатывать все нейронные сети, какие захотите, привлекать всех исследователей, но без разметчиков у вас не будет ChatGPT. У вас ничего не будет.
— Алексей Савре, один из сотрудников
Разметка данных — это важный процесс анализа образцов данных для помощи автоматизированным системам в лучшем распознавании конкретных элементов в наборе данных. Разметчики маркируют определенные элементы (будь то отдельные изображения или виды текста), чтобы машины могли научиться лучше определять их самостоятельно. Таким образом, люди помогают автоматизированным системам точнее отвечать на запросы пользователей и играют большую роль в обучении моделей машинного обучения.
Однако, несмотря на важность этой работы, NBC отмечает, что большинство модераторов получают небольшую оплату за свою работу. В случае с модераторами OpenAI разметчики данных не получают никаких льгот и получают оплату, которая едва превышает минимальную заработную плату в некоторых штатах. Савре проживает в Канзас-Сити, где минимальная заработная плата составляет $7,25.
Но такая оплата все же выше по сравнению с прошлыми практиками компании. Ранее OpenAI передавала работу модераторам в Африке, где из-за низких зарплат и ограниченных трудовых законов им удалось оплачивать труд работникам всего лишь $2 в час. OpenAI ранее сотрудничала с компанией Sama, американской фирмой, заявляющей о своей преданности «этической цепочке поддержки искусственного интеллекта», но основной сферой деятельности которой является связь крупных технологических компаний с низкооплачиваемыми контрактными сотрудниками из стран третьего мира. Sama была обвинена в суде в предоставлении плохих условий труда. Модераторы с низкими зарплатами из Кении в конечном итоге помогли OpenAI создать систему фильтрации, которая могла отсеивать неприятные или оскорбительные материалы, отправленные в чат-бот. Однако для выполнения этой работы модераторам пришлось просматривать множество подобных материалов, включая описания убийств, пыток, сексуального насилия и инцеста.
Искусственный интеллект может казаться волшебством — оживать и отвечать на запросы пользователей, как по заклинанию. Однако на самом деле его работа поддерживается армией незаметных людей, которые заслуживают лучшего вознаграждения за свой вклад.


Ван 25 лет. Она работала секретарём в приёмной, однако когда в 2017 году её компания закрылась, друг, работавший разработчиком алгоритмов, предложил ей исследовать новый карьерный путь в аннотировании данных — процессе разметки данных, позволяющем применять их в системах искусственного интеллекта, особенно с использованием машинного обучения с учителем. Став безработной, она решила рискнуть.
Два года спустя Ван уже работала помощником проект-менеджера в пекинской компании Testin. Обычно она начинает свой рабочий день со встречи с клиентами, которые в основном представляют китайские технологические компании и стартапы в сфере AI. Клиент сначала передаёт ей в качестве теста небольшую долю массива данных. Если результаты удовлетворяют требованиям, Ван получает массив данных полностью. Затем она передаёт его производственной команде, обычно состоящей из десяти разметчиков и трёх контролёров. Такие команды настроены на эффективность и могут, например, аннотировать 10 тысяч изображений для распознавания дорожных полос примерно за восемь дней с точностью в 95%.
«Эта работа полностью зависит от терпения, понимания разметки данных и деталей», — рассказывает Ван, которая как и все разметчики Testin, получила после приёма на работу подробное обучение.

Современных разметчиков данных иногда называют «рабочей силой AI» или «невидимыми трудягами эпохи AI». Они аннотируют данные, используемые для обучения моделей, которые позволяют всем нам пользоваться товарами и услугами, дополненными возможностями машинного обучения.
Тридцать лет назад системы компьютерного зрения едва могли распознавать рукописные цифры. Однако сегодня машины с поддержкой AI используются для управления беспилотными автомобилями, выявления злокачественных опухолей на снимках и проверки юридических договоров. Наряду с современными алгоритмами и мощными вычислительными ресурсами ключевую роль в ренессансе AI играют тщательно размеченные массивы данных.
Растущий спрос на размеченные данные привёл к росту компаний, использующих армии опытных разметчиков данных (как внутренние, так и на аутсорсе) и разрабатывающих функциональные инструменты аннотирования для профессиональных сервисов разметки. Так как объёмы работ таких компаний увеличились, выросла и их рыночная стоимость.
Рост объёмов сервисов разметки данных
Этим летом разметка данных попала в заголовки многих СМИ благодаря тому, что стартап разметки данных Scale AI из Сан-Франциско получил в раунде финансирования $100 миллионов. Основанный в 2016 году 22-летним выпускником МТИ Scale AI стал одним из самых «горячих» AI-стартапов Кремниевой долины.
Ключевым фактором, повлиявшим на высокую рыночную стоимость Scale AI, стал его широкий спектр профессиональных сервисов разметки данных, в частности, для его клиентов в сфере беспилотного вождения: Waymo, Lyft, Zoox, Cruise и Toyota Research Institute. TechCrunch сообщает, что Scale AI набрал при помощи краудсорсинга почти 30 тысяч сотрудников для разметки текста, аудио, изображений и видео.

Mighty AI (ранее известная как Spare5) — это ещё одна популярная компания в сфере разметки данных. Эта компания из Сиэттла была приобретена в июне гигантом автоперевозок Uber за нераскрытую сумму; покупка считается одним из шагов Uber в рамках активной инициативы по внедрению технологий беспилотного вождения. Основанная в 2014 году Mighty AI тоже использует для разметки данных огромную команду проверенных и надёжных аннотаторов.
Это новое поколение компаний, занимающихся разметкой данных, имеет множество общих черт: они обособляют себя от традиционных краудсорсинговых платформ наподобие Amazon Mechanical Turk, называя свои услуги «управляемыми сервисами разметки данных», предоставляющими размеченные для конкретной предметной области данные с упором на контроль качества. Их разметчики при помощи краудсорсинга путём строгого процесса найма собраны со всего мира, после чего прошли превосходное обучение и получили высококлассное руководство. А их внутренние команды разработки постоянно проводят исследования и создают новые алгоритмы AI, помогающие ускорять процессы ручного аннотирования.
Кроме внутренних команд разметки данных технологические компании и стартапы в сфере беспилотного вождения активно используют эти управляемые сервисы разметки. Нам сообщили, что некоторые компании из сферы беспилотного вождения ежемесячно платят компаниям, занимающимся разметкой данных, миллионы долларов.
2019 год стал свидетелем взрывного развития множества массивов данных для беспилотного вождения. Waymo, подразделение Ford под названием Argo AI, занимающееся беспилотным вождением, и Lyft выложили в открытый доступ высококачественные массивы для беспилотного вождения. Это стало радостным известием для исследователей задач беспилотного вождения со всего мира.
Создание высококачественного массива данных для беспилотных автомобилей — гораздо более сложная задача, чем, например, создание массива для классификации изображений с размеченными кошками. В Waymo Open Dataset представлено примерно три тысячи сцен для вождения, суммарно составляющих 16,7 часов видеоданных, 600 тысяч кадров, приблизительно 25 миллионов ограничивающих 3D-параллелепипедов и 22 миллиона ограничивающих 2D-прямоугольников. И это составляет лишь крошечную долю от огромной закрытой базы данных беспилотного вождения Waymo.

Ведущий китайский поставщик технологий беспилотного вождения Baidu Apollo рассказал нам, что типичный высококачественный массив данных для беспилотного вождения обычно содержит следующие элементы:
- попиксельная семантическая аннотация;
- семантическая 3D-аннотация;
- попиксельная аннотация экземпляров объектов;
- подробная сегментация дорог;
- траектории движущихся объектов;
- высокоточная информация GPS/IMO и так далее.
Сама природа их бизнеса накладывает на компании, занимающиеся беспилотным вождением, строгие требования к качеству аннотаций. Например, языковой массив данных может всего лишь ошибочно спрогнозировать нецензурное слово в текстовом сообщении, а любые ошибки в массиве для беспилотного вождения могут иметь на дорогах общего пользования катастрофические последствия.
В прошлом году Калифорнийский университет в Беркли представил BDD100K — крупнейший на тот момент опенсорсный массив данных для беспилотного вождения, составленный из более чем ста тысяч видео сцен вождения. Один из главных контрибьюторов BDD 100K Фишер Ю сообщил нам, что из-за опасений низкого качества данных, обеспечиваемых традиционными краудсорсинг-платформами, университет отдал проект на аутсорс стороннему управляемому сервису.
«Разметчикам-краудсорсерам сложно гарантировать точность данных высококачественной сегментации или ограничивающих прямоугольников в массивах данных для беспилотного вождения. Поэтому компании склоняются к тому, чтобы рассчитывать на собственные команды или на сторонние сервисы», — говорит Ю.
Мусор на входе, мусор на выходе
Hengdian World Studios, также известная как «Чайнавуд» — крупнейшая киностудия Азии. Акры фермерской земли в центральной части китайской провинции Чжэцзян были превращены во множество съёмочных студий и площадок, на которых тысячи китайских актёров и актрис снимают для фильмов, телешоу и Интернет-драм.
Вышеупомянутая китайская компания Testin, предоставляющая сервисы данных, тоже создала себе базу в Hengdian. Она не снимает здесь телешоу: в студии проводят фото- и видеосъёмку выражений лиц актёров (смеха, плача, ярости и так далее), которые используются для разметки ключевых точек лиц для китайских AI-компаний.

Testin была основана в 2011 году и изначально была платформой сервисов для тестирования производительности мобильных приложений. Со всемирным ростом популярности и потенциала искусственного интеллекта компания запустила в 2017 году собственный дата-бизнес, предоставляющий специализированные данные и соответствующие аннотации. Сегодня Testin может похвастаться внутренней командой из более чем тысячи разметчиков.
Китайские технологические компании на собственной шкуре испытали принцип «мусор на входе, мусор на выходе». За последние годы они подняли свои требования к точности, сложности, объёмам, времени и так далее. В прошлом году закрылись многие низкобюджетные китайские компании, занимающиеся разметкой данных, потому что они не могли обеспечивать соответствие новым высоким стандартам.
Главный управляющий по сервисам данных Testin Генри Цзя сообщил нам следующее: «В 2015-2016 годах AI-компании могли создать хороший прототип AI-решения на основании опенсорсных массивов данных или публично доступных в Интернете данных и получить финансирование. Но если они действительно хотели реализовывать алгоритмы в реальном мире, им приходилось повышать планку качества данных».
Цзя взял для примера разметку ключевых точек лиц. Несколько лет назад эта задача была гораздо проще, разметчикам достаточно было указать серию точек на человеческом лице. Сегодня в разметке ключевых точек лица может быть задействовано до 206 точек, от восьми и более на каждую бровь, от двадцати и более на губы, от семнадцати и более вдоль линии подбородка, и так далее.

Также Цзя сообщил, что ключевую роль в разметке также играет знание предметной области. Большинство низкобюджетных разметчиков аннотировало только относительно низкоконтекстуальные данные и не могло обрабатывать высококонтекстуальные данные, например, классификацию юридических договоров, медицинских снимков или научной литературы. Для этого требуются знания специалистов в предметных областях. Было доказано, что водители обычно размечают массивы данных для беспилотного вождения эффективнее, чем люди без водительских прав, то же относится к врачам, патологоанатомам, радиологам (или к людям, имеющим хотя бы связанное со здравоохранением образование): они лучше справлялись с точной разметкой медицинских снимков. Однако труд специалистов дорог.
Уилсон Панг — главный технический директор сиднейской компании Appen, занимающейся аннотированием данных, имеющей опыт в более чем 180 языках и насчитывающей более одного миллиона краудсорсинговых сотрудников в более чем 130 странах. Панг рассказал нам, что при покупке данных компаниями цена больше не является самых существенным решающим фактором. «Если качество данных недостаточно, точность AI-моделей окажется неудовлетворительной. Когда такое происходит, людям обычно нужно повторно собирать и аннотировать данные, из-за чего впустую тратится большая часть времени дата-саентистов, а также возникают дополнительные аппаратные расходы на обучение этих моделей. Но самое важное то, что если компаниям не удастся приобрести высококачественные данные, они также потеряют время и конкурентоспособность», — говорит Панг. В марте этого года Appen приобрела компанию Figure Eight (ранее называвшуюся Crowdflower) из Сан-Франциско, которая занимается высококачественной разметкой данных. Сообщается, что сумма сделки составила $300 миллионов.
Инструмент разметки с помощью машинного обучения
Чтобы применить 2D-карту сегментации к транспортному средству на видеокадре, Юрий Борисов дважды щёлкает мышью, создавая вокруг автомобиля ограничивающий прямоугольник, а затем ждёт, пока изобретённый им инструмент с помощью машинного обучения сделает всё остальное — быстро определит контур автомобиля. Он утверждает, что этот инструмент повысил его эффективность разметки данных в десять раз.
Борисов получил кандидатскую степень по computer science в Московском государственном университете. Два года назад он стал сооснователем Supervise.ly — стартапа Кремниевой долины, занимающегося разработкой ПО, предназначенного для ускорения аннотирования данных для моделей глубокого обучения. Платформа Supervise.ly сейчас используется более чем 15 тысячами компаний и инженеров, в основном из таких промышленных секторов, как сельское хозяйство, строительство, потребительская электроника, здравоохранение и беспилотный транспорт.

Supervise.ly — одна из множества программных компаний, успевших за последние несколько лет воспользоваться ажиотажем вокруг аннотирования данных. Борисов утверждает, что рост компании был вызван бумом спроса на сложную и длительную работу по аннотации данных, например, по сегментированию волос или разметке видео. «На самом деле, не важно, сколько других аннотаторов участвует в процессе сегментации волос. Главное здесь — качество и очень точная попиксельная разметка».
По словам Джона Синглтона, сооснователя компании Watchful, занимающейся ПО для разметки данных, многие компании, которым требуются качественно размеченные данные, имеют относительно мало опыта в data science и машинном обучении, а также обладают ограниченными бюджетами на AI-проекты.
«Очень часто аннотацией данных занимаются и так уже перегруженные команды дата-саентистов, неспособные сфокусироваться на своей работе, которая заключается в разработке и внедрении практичных моделей», — рассказывает Синглтон.
Для Watchful и Supervise.ly эти мелкие и средние клиенты представляют собой расширяющийся рынок инструментов машинного обучения, которые, по сути, позволят усилить их возможности по выделению сигнала из данных. Согласно новому исследованию Grand View Research, предполагается, что к 2025 году мировой рынок инструментов аннотирования данных достигнет $1,6 миллиарда.
Существует несколько методик аннотирования данных с помощью машинного обучения. Юрий Борисов рассказал нам о методике «human-in-the-loop», при которой пользователь сначала применяет к неразмеченным изображениям предварительно обученную модель сегментирования, автоматически создающую грубую маску. Затем пользователь вручную редактирует контур маски. Примером использования такой методики является Polygon RNN — исследовательский проект, разработанный Торонтским университетом и NVIDIA с целью эффективного аннотирования массивов данных сегментации.
Supervise.ly также спроектировала модель интерактивной разметки. Как показано ниже, пользователь сначала помещает объект в ограничивающий прямоугольник, а затем модель создаёт приблизительный контур и прогнозирует класс/предметную область объекта. Пользователь может отредактировать прогноз модели простым нажатием мыши: зелёный цвет означает верный прогноз, красный — ошибочный.

По словам главного технического директора Kaggle Бена Хаммера, ещё одной популярной темой стало активное обучение. На недавнем мероприятии Seed Award, проводимом в Сан-Франциско, Хаммер рассказал нам, что «активное обучение применяется для определения того, какие примеры данных стоит классифицировать, а какие стоит размечать живому человеку. Человек классифицирует только те случаи, которые машины пока не знают, или сильно в них неуверены».
Исследования аннотирования данных в научных кругах
«Как я могу использовать представленный вами инструмент аннотирования данных?», — такой вопрос чаще всего задавали Хуаню Лину на конференции Computer Vision and Pattern Recognition (CVPR) 2019, проводившейся в Лонг-Бич (Калифорния).
Лин — аспирант Торонтского университета, работающий в Vector Institute. Его исследовательская команда представила статью Fast Interactive Object Annotation with Curve-GCN. Главной инновацией этого исследования стало использование графовой свёрточной сети (Graph Convolutional Network, GCN) для автоматического создания контура объекта. В экспериментах этот сквозной фреймворк превосходил по производительности все существующие методики и в автоматическом, и в интерактивном режимах.
Научный руководитель Лина — профессор Санджа Фидлер, уважаемая исследовательница, руководящая торонтской лабораторией разработок AI компании NVIDIA. Её команда приложила много усилий к сегментации объектов и разметке изображений, а сама она сделала свой вклад в создание PolyGon RNN и её улучшенной версии, PolyGon RNN++. Новая методика с использованием GCN продемонстрировала десятикратное (в автоматическом режиме) и стократное (в интерактивном режиме) ускорение по сравнению с PolyGON RNN++. Доклад Лина на CVPR 2019 был с энтузиазмом воспринят посетителями.

Лин рассказал нам, что самыми актуальными нерешёнными проблемами в аннотировании данных остаются 3D-разметка и аннотирование видео. По мнению главного технического директора Appen Панга, современные техники отслеживания объектов уже способны упростить разметку видео. Живые разметчики аннотируют объекты на первом кадре, после чего алгоритм отслеживает эти объекты на последующих кадрах. Человеку нужно редактировать работу алгоритма только тогда, когда отслеживание работает неверно. Эта методика позволяет аннотировать видео в сто раз быстрее, чем с этим справляются живые разметчики вручную.
Большинство инсайдеров, с которыми мы провели интервью, согласно с тем, что методики машинного обучения, требующие меньшего объёма размеченных данных (например, обучение со слабым контролем, обучение few-shot и обучение без учителя) достигли многообещающих результатов. Однако общее мнение таково, что бизнес аннотирования изображений продолжит расти.
«Обучение с учителем — по-прежнему самый эффективный подход для AI-решений, особенно для самых инновационных систем, и я не вижу признаков того, что в ближайшее время ситуация изменится», — говорит Панг.
Лэй Ван смотрит на свою карьеру и будущее с оптимизмом. Она хорошо проявляет себя на должности помощника проект-менеджера и вскоре возглавит собственную команду аннотирования данных. Придя в Testin, она почти ничего не знала об AI, но работа вызвала у неё максимальный интерес к этой теме. Она часто обсуждает исследования и алгоритмы со своим другом-инженером, а также внимательно следит за новостями про AI, чтобы понимать, куда может привести её эта быстро эволюционирующая технология.
- data labeling
- computer vision
- машинное обучение
- data annotation
- software
- dataset
- Training Data
- разметка данных
- Data Mining
- Обработка изображений
- Big Data
- Машинное обучение
- Искусственный интеллект

«Я выгляжу в основном как код на языке программирования», — отвечает голосовая помощница Алиса на вопрос о ее внешности. Она включает музыку, ставит будильник, но, кроме того, поддерживает отвлеченную беседу почти как человек. Сценарии диалогов для нее прописали разработчики, но еще машину нужно научить верно выбирать ответы, которые будут восприниматься естественно и логично. Эту работу в том числе помогают выполнять специальные люди — разметчики данных.
Все как в школе: чем больше помощница узнает верных ответов, тем лучше она поддерживает беседу. Если ответом на обезличенный фрагмент вопроса «Как ты выглядишь?» были слова «Да, зеленый», то разметчик отметит этот диалог как неестественный, ведь реплика логически не связана с предшествующим вопросом. А ответ «Беседы на такие темы — не мое» признает нейтральным — такой фразой можно ответить практически на любой вопрос.
Два года назад сооснователь Dbrain и R-Sept Алексей Хахунов в материале «Афиши Daily» говорил о разметчиках данных как о представителях новой профессии, которая появится с развитием искусственного интеллекта. Сегодня эти люди работают в сервисах «Яндекс.Толока», Handl или Labelbox, а для некоторых разметка уже стала источником регулярного заработка.
«Потребность в разметке данных людьми возникла, когда началось индустриальное применение технологий машинного обучения: алгоритмам нужно обучаться на данных, и зачастую их невозможно получить, пока их не создаст человек.
Первые разметчики данных, которые изучали случайную анонимизированную пару «поисковый запрос — нашедшийся документ» и оценивали, насколько найденный документ релевантен запросу пользователя, появились [в «Яндексе»] еще в 2008–2009 годах.

Десять лет назад ручная разметка данных в «Яндексе» начиналась с нескольких людей, которые заполняли таблицы в Excel. А в 2014 году появилась платформа «Яндекс.Толока», где каждый может выступить и в роли заказчика, и в роли исполнителя. Сейчас каждый день там размечают десятки миллионов единиц данных для сотен разных проектов. И мы ожидаем, что до конца 2020 года в выполнении заданий поучаствуют более 6 млн человек».
Пенсионерка Марина Степанова из Сочи выбрала работу разметчицы данных три года назад. «Я искала подработку. Перепробовала много разных сайтов, копирайтинг, где вроде работаешь, вкладываешься, а получаешь копейки. В итоге остановилась на «Толоке», — говорит она. — Сначала работа не пошла: было неинтересно, тяжеловато с первой попытки, так что я это дело оставила. Вернулась спустя примерно год, и в этот раз получилось. Чем больше я работала, тем более понятной становилась система».
Разметчики на «Толоке» составляют собственный график подработки. Кто‑то, как Степанова, занимается этим каждый день. «Утром встаю иногда в 8.00, иногда — в 10.30, кофе попила и включаю компьютер, — рассказывает она. — Но это не значит, что в это время для меня уже есть любимые задания. Я провожу в «Толоке» не все время — занимаюсь своими делами и периодически захожу туда. И так до 9 часов вечера. Заработки очень маленькие, буквально по центу цепляешь, и чтобы что‑то заработать, [надо работать целый день]».
Студент IT-направления Кирилл рассказал «Афише Daily», что уже два года каждый день подрабатывает на разметке. «Сначала уделял заданиям порядка двух-трех часов по три-четыре дня в неделю, — говорит он. — Сейчас же в условиях удаленного обучения могу уделять по четыре-пять часов пять дней в неделю».
Разметчик Алексей Дубровин из Улан-Удэ заходит на сайт время от времени. «Весной, когда был период самоизоляции и все сидели на удаленке, работы стало меньше, а свободного времени — больше. Я случайно наткнулся на «Толоку» и попробовал, что из этого получится, — говорит он. — Времени на выполнение заданий уделяю иногда час, иногда два, иногда 10–15 минут».
Все эти разметчики — фрилансеры. Они не занимаются разметкой ни в штате «Яндекса», ни в какой‑либо другой компании. Заказчики публикуют на платформе задания, описывают условия и устанавливают стоимость. Многие разметчики не имеют специальных знаний, но иногда для обучения машинного интеллекта требуются квалифицированные специалисты, например, чтобы отметить место перелома на снимках и проанализировать решения суда.
Здесь и далее — примеры заданий на «Яндекс.Толоке»

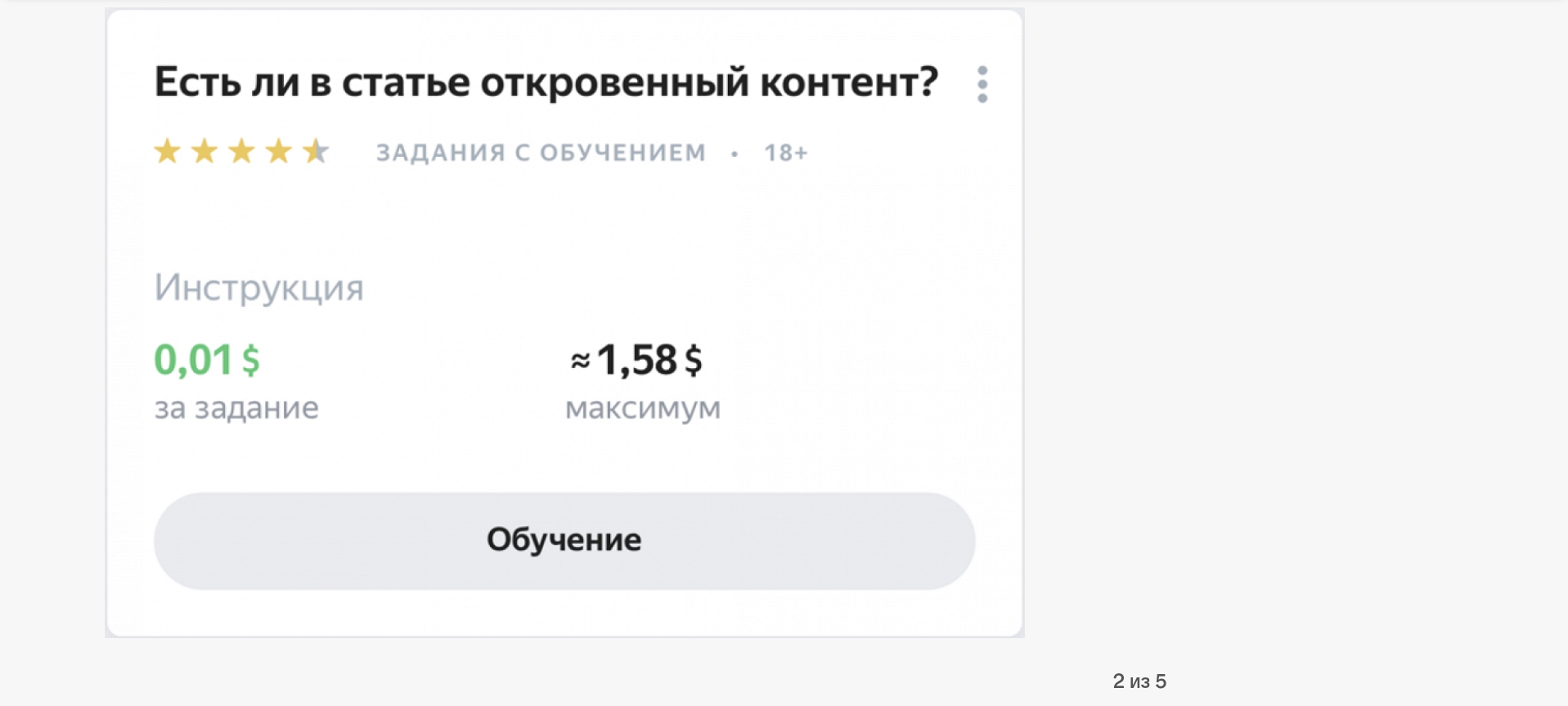

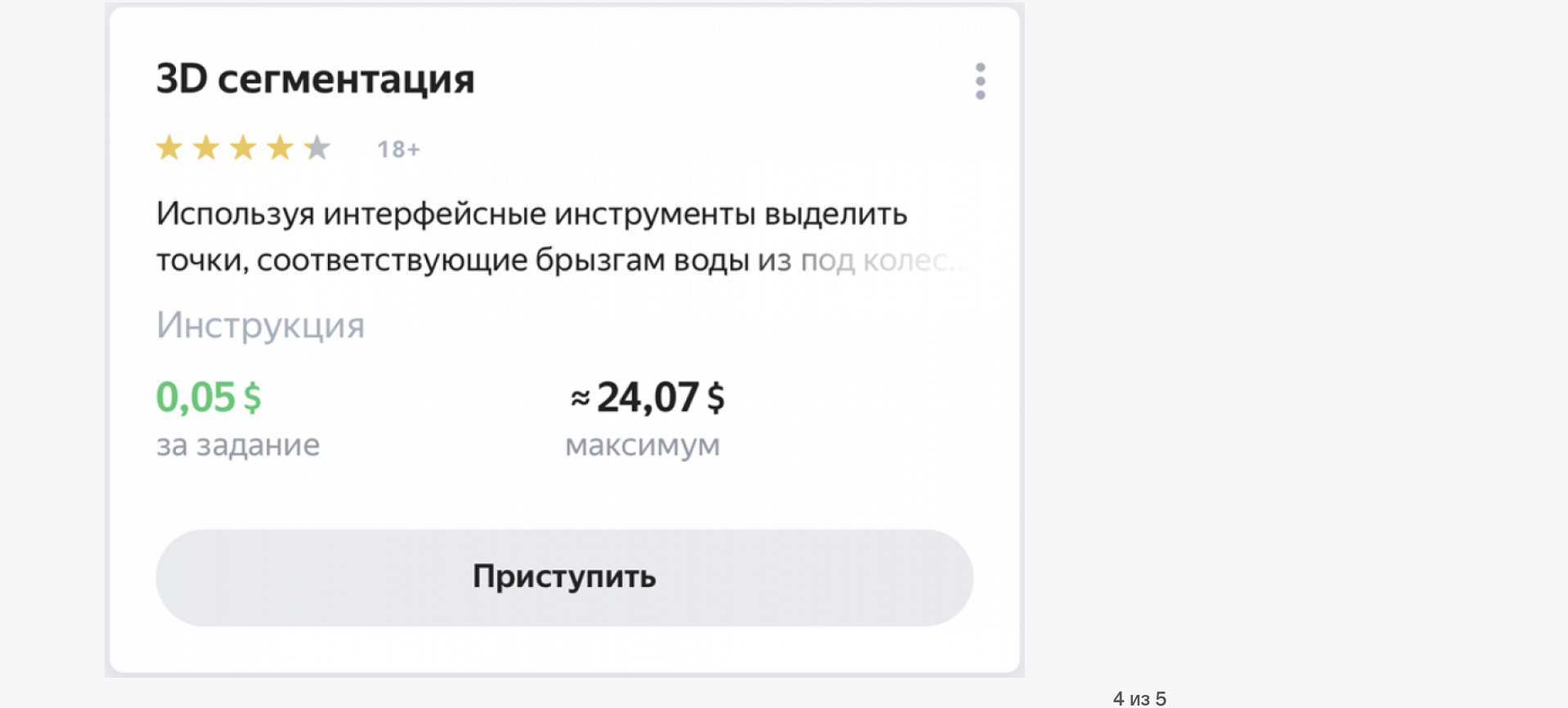

«Типов разметки очень много, и обычно цель каждого задания — это сбор обучающих примеров или проверка работы алгоритмов машинного обучения, — объясняет руководитель «Яндекс.Толоки». — Например, задачи по классификации объектов часто используют для модерации контента, лингвистические задачи вроде выделения сущностей в тексте — для обучения чат-ботов и голосовых помощников, разметку объектов на изображениях — для систем компьютерного зрения».
Это настолько объемная работа, что на сбор, очистку и маркировку данных уходит около 80% времени всего процесса машинного обучения. «Большинство заданий связано с обработкой небольших объектов: например, посмотреть на картинку и указать, что на ней изображено, — продолжает Мегорская. — Или из двух вариантов перевода выбрать лучший. Выделить в тексте все числительные или обвести на картинке определенный объект — например, дорожный знак или автомобиль».
Говоря о любимых заданиях, Степанова вспоминает то, в котором надо было высказать мнение об отрывках из мультфильмов, документальных и художественных фильмов: написать, нравится ли он, готовы ли добавить его в коллекцию. Дубровин отмечает задания, связанные с переводом. «По образованию я филолог, но работаю не по специальности, — объясняет он. — А выполнение таких заданий позволяет освежать знания». Кириллу же нравятся задания по модерации контента и обучению Алисы. Причина та же: интерес к теме и расширение кругозора.
Разметчики рассказывают, что с некоторыми заданиями возникают вопросы. «Бывает, открываю задание и понимаю: надо зайти, открыть сайт, посмотреть, правильно ли он сделан, оценить по критериям, — говорит Степанова. — А оплату предлагают — 1 цент. Эта работа не стоит того. Или просят собрать информацию о малоизвестном актере, указать, в каких фильмах он участвовал. Это гигантская работа, а платят за нее так же — цент».
У Кирилла бывают проблемные «пешеходные» задания, в которых нужно собирать информацию об организациях. «Исходные данные о них могут оказаться устаревшими, поэтому, отправляясь на задание, вы можете и не найти эту организацию вовсе, — жалуется он. — Компенсацию, конечно, заплатят, но это не очень приятно, когда ожидаешь 0,15 доллара, а получаешь 0,07 доллара».
Даже при регулярном выполнении заданий доход не будет постоянным, отмечают разметчики. В неделю можно заработать от пары долларов до сотни. «Мой самый большой заработок [за сутки] составил 15–16 долларов, — делится Степанова. — С 8 часов вечера до 9 часов утра я выполняла задания, где нужно было определить, относится ли документ к научной статье. Приводились записи лекций, методички, просто художественная литература. За одно задание давали цент, но именно на нем я заработала больше всего. К утру уже не могла, засыпала, в глазах рябило, было сложно сидеть. Но когда у тебя девять минут на задание, не отойдешь даже кофе попить».

«Мы видим, что потребность в разметке данных для искусственного интеллекта стремительно растет, причем не только в России, но и во всем мире. Высокий спрос на услуги «Толоки» есть как среди крупнейших технологических компаний в России, так и за ее пределами (на сайте «Толоки» указано, что услугами платформы, помимо сервисов «Яндекса», пользуются Ozon, Samsung Research Russia, AliExpress, «Авито», «Рамблер», «Тинькофф Банк» и другие компании. — Прим. ред.). В «Толоке» появляется все больше и иностранных заказчиков, и толокеров из разных уголков мира: Азии, Африки, Северной и Южной Америки.
Нет, пожалуй, ни одного сервиса и продукта «Яндекса», который бы не использовал «Толоку» для своих задач. Поиску она нужна для обучения алгоритмов ранжирования, Алисе — для тестирования моделей синтеза речи, «Такси» — для контроля чистоты автомобилей, «Дзену» — для классификации контента, беспилотникам — для обучения алгоритмов навигации и так далее».
Есть все основания полагать, что разметка данных войдет в список профессий будущего. Она относится к сфере обслуживания высоких технологий, которая, по мнению Брукингского института, со временем будет только расти, а не сокращаться, как профессии из сферы логистики и администрирования. В США на разметку данных уже переходят люди из сельского хозяйства или промышленности, которые потеряли работу из‑за автоматизации.
Разметчики работают удаленно, чтобы зарабатывать, им нужны только ноутбук или телефон и выход в интернет. Это удобно не только для исполнителей, но и для заказчиков. Около 64% миллениалов предпочли бы иногда работать из дома, ведь это сокращает время на дорогу до офиса, на которую в среднем тратят 54 часа в год. Число работодателей, готовых перевести часть сотрудников на удаленку, достигло в России 20%, в то время как в США их уже больше 75%.
Стоит ожидать появления больших международных бирж по разметке данных, на которых заказчики из более развитых стран смогут найти исполнителей из развивающихся, где курс доллара высок по отношению к национальной валюте. За разметку данных в США компаниям приходится платить 7–15 долларов в час, но если делать ее в Малайзии, то цена снизится до 2,5 доллара в час. В итоге разработчики смогут сэкономить на разметке, а люди — получить высокую по местным меркам оплату за простые задания.


